目录
一、过采样介绍
(一)什么是过采样
(二)过采样的优点
(三)过采样的缺点
二、欠采样介绍
(一)什么是欠采样
(二)欠采样的优点
(三)欠采样的缺点
三、基于聚类的欠抽样方法(K-Means欠采样/KMeans-Undersampling)
(一)KMeans欠采样原理及其步骤介绍
(二)为什么不采用简单的欠采样或者过采样而选择Kmeans欠采样
(三)聚类结束后,如何确定多数类样本欠抽样的数据量,并从每个簇中选择样本?------类别权重调整
(1)确定多数类样本欠抽样的数据量-----类别权重调整
(2)从每个簇中选择样本
四、python实现K-Means欠采样
(一)生成数据集
(二)目的
(三)通过Kmeans对X1多数类样本进行聚类
(1)通过手肘法和目标函数确定KMeans的最优K值
(2)选择最优K值后,进行KMeans聚类
(3) 查看每个聚类后类别中的样本数
(4) 计算聚类后每个类别占多数类样本的比例
(5)计算聚类后每个类别中应该抽取的样本数
(6)抽取数据
①随机无放回抽取33个标签为0的样本
②随机无放回抽取30个标签为1的样本
③随机无放回抽取50个标签为2的样本
④随机无放回抽取52个标签为3的样本
④随机无放回抽取15个标签为4的样本
⑤合并各类抽取后的数据
(四) 将180个多数类样本,和90个少数类样本进行整合。(目标就是多数类样本:少数类样本=2:1)
五、基于聚类的过抽样方法(K-Means过抽样)
六、python实现KMeans过抽样
(一)目的
(二)通过Kmeans对X2少数类样本进行聚类
(1)通过手肘法和目标函数确定KMeans的最优K值
(2)选择最优K值后,进行KMeans聚类
(3) 查看每个聚类后类别中的样本数
(4) 计算聚类后每个类别占少数类样本的比例
(5)计算聚类后每个类别中应该抽取的样本数
(6)抽取数据
①随机无放回抽取2个标签为0的样本
②随机无放回抽取2个标签为1的样本
③随机无放回抽取3个标签为2的样本
④随机无放回抽取3个标签为3的样本
⑤合并各类抽取后的数据
(三) 将200个多数类样本,和100个少数类样本进行整合。(目标就是多数类样本:少数类样本=2:1)
一、过采样介绍
(一)什么是过采样
过采样是一种处理数据不平衡问题的方法,特别是在分类问题中,当某个类别的样本数量远远少于其他类别时,会导致模型在训练和预测中对少数类别的识别能力下降。过采样的主要目的是增加少数类别的样本数量,以改善数据的平衡。

(二)过采样的优点
1. 提高模型对少数类别的识别能力:通过增加少数类别的样本数量,使得模型更容易学习并识别少数类别的特征,从而提高模型在少数类别上的性能。
2. 不丢失信息:过采样生成的新样本是基于原始数据生成的,因此不会丢失原始数据的信息,保留了数据的特征。
(三)过采样的缺点
1. 容易引入噪声:过采样生成的新样本可能并不完全符合真实数据分布,可能会引入噪声,导致模型过拟合。
2. 增加计算复杂度和训练时间:过采样会增加数据集的大小,从而增加模型的计算复杂度和训练时间,尤其是在数据量较大的情况下。
二、欠采样介绍
(一)什么是欠采样
欠采样是一种处理数据不平衡问题的方法,与过采样相反,它是通过减少多数类别的样本数量来实现数据平衡,从而解决在分类问题中多数类别样本数量远远大于少数类别样本数量的情况。

(二)欠采样的优点
1. 减少训练时间和计算复杂度:由于减少了多数类别的样本数量,可以减少模型的训练时间和计算复杂度,提高训练效率。
2. 降低过拟合的风险:减少多数类别的样本数量可以降低模型对多数类别的过度拟合,使得模型更加泛化。
(三)欠采样的缺点
1. 可能丢失重要信息:欠采样会舍弃多数类别的样本,可能会丢失一些重要信息,导致模型在多数类别上的性能下降。
2. 容易丢失少数类别的特征:由于减少了多数类别的样本数量,模型可能无法充分学习到少数类别的特征,导致在少数类别上的性能下降。
三、基于聚类的欠抽样方法(K-Means欠采样/KMeans-Undersampling)
(一)KMeans欠采样原理及其步骤介绍
KMeans欠采样是一种处理不平衡数据集的方法,它结合了聚类和欠采样的思想,通过聚类的方式选择代表性样本,以平衡数据集并提高模型性能。
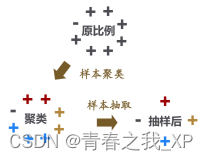
具体步骤如下:
1. 数据预处理:对数据进行预处理,包括缺失值处理、数据标准化等。
2. KMeans聚类:使用KMeans聚类算法对数据的多类样本数据进行聚类,将数据分成K个簇。
3. 选择代表性样本:从每个簇中选择代表性样本,可以选择簇中的中心点或者随机选择一个样本,若在这个簇中需要选取多个样本,可以考虑有放回选取和无放回选取,建议采用无放回选取
4. 构建新的数据集:将选择的代表性样本组成新的数据集,用于模型训练和预测。
5. 模型训练和预测:使用新的数据集训练模型,并对测试集进行预测。
通过KMeans欠采样,可以有效地平衡数据集,提高模型对少数类样本的学习能力,从而提高分类性能。
(二)为什么不采用简单的欠采样或者过采样而选择Kmeans欠采样
简单的欠采样和过采样方法在处理不平衡数据集时存在一些问题,比如欠采样可能导致信息丢失,过采样可能引入噪声。
KMeans欠采样是一种结合了聚类和欠采样的方法,可以一定程度上克服简单欠采样和过采样的缺点,具有以下优点:
1. 保留数据分布特征:KMeans欠采样通过聚类的方式选择代表性样本,能够更好地保留原始数据的分布特征,避免了简单欠采样可能导致的信息丢失问题。
2. 减少噪声引入:KMeans欠采样在选择样本时考虑了样本之间的相似性,避免了简单过采样可能引入的噪声问题,提高了模型的泛化能力。
3. 降低计算成本:KMeans欠采样通过聚类的方式减少了样本数量,可以降低模型训练和预测的计算成本,提高了效率。
4. 提高分类性能:KMeans欠采样能够更好地平衡数据集,提高了模型对少数类样本的学习能力,从而提高了分类性能。
综上所述,KMeans欠采样是一种比简单欠采样和过采样更加有效的处理不平衡数据集的方法,能够在一定程度上解决不平衡数据集带来的挑战,提高模型性能。
(三)聚类结束后,如何确定多数类样本欠抽样的数据量,并从每个簇中选择样本?------类别权重调整
(1)确定多数类样本欠抽样的数据量-----类别权重调整
前提:正类数量:负类数量>真实世界的真实比例
在处理二分类问题时,我们经常遇到正类和负类样本数量不平衡的情况。假设在一个实际的二分类问题中,正类的样本数量为 N1,而负类的样本数量为N2,并且 N1显著大于 N2。N1/N2的比例远大于真实世界这两种类别的比例。
一旦我们知道了真实的正负类比例ratio,我们可以使用这个信息来调整训练数据,使得模型训练过程中的样本分布更加接近真实世界的分布。为了达到这个目的,我们可以采用KMeans欠采样策略,以负类样本的数量N2作为基准,对正类样本进行欠采样。
通过欠采样,我们希望获得的新的正类样本数量 N1_new 应该与负类样本数量N2成比例,
即:
N1_new=ratio*N2
这就是通过进行类别权重调整,来确定多数类样本欠抽样时的数据量。
这样,经过欠采样后的正类样本数量 将更接近于实际情况下的正负类比例,有助于提高模型的泛化能力和避免过拟合。
补充:这个ratio我们也可以人为的设定
(2)从每个簇中选择样本
上边我们确定了多数类样本也就是正类样本进行欠抽样的数据量N2_new
那么怎么从K个簇中,每个簇中抽取样本呢?
首先,确定从每个簇中抽取的样本量ni:
ni=(N1_i/N2)*N1_new
i=1,2,3,4,5,6......k(k个簇)
其中N1_i,代表聚类后第i个簇中的样本量,N1_i/N1代表第i个簇中的样本量占整个多类样本数量的比例
ni也就是确定的每个簇中抽取的样本量
每次从各个簇中抽取样本时,建议采用不放回抽样,这样可以保证尽量不丢失原始数据的信息,保留数据的特征。
四、python实现K-Means欠采样
(一)生成数据集
import numpy as np
from sklearn.datasets import make_blobs
X1, Y1 = make_blobs(n_samples=200, centers=1, random_state=0)
X2, Y2 = make_blobs(n_samples=90, centers=1, random_state=0)
X = np.vstack((X1, X2))
Y = np.hstack((Y1, Y2 + 1)) # 将第二个类别的标签设置为1,以便与第一个类别区分开如果想要控制每个类别的数量,可以使用n_samples参数分别设置每个类别的数量,然后使用numpy库将数据合并。例如,生成200个样本属于第一个类别,90个样本属于第二个类别:.
import pandas as pd
# 将 Y 转换为 Pandas Series
Y_series = pd.Series(Y)
# 计算 Y 中每个类别的数量
class_counts = Y_series.value_counts()
print(class_counts)

(二)目的
我们想控制Y1类和Y2类的数量比例ratio是2:1,故若采取欠抽样的话,需要从Y1的的样本中抽取出180个样本量,或者说去除20个样本量 。
(三)通过Kmeans对X1多数类样本进行聚类
(1)通过手肘法和目标函数确定KMeans的最优K值
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
# 使用手肘法确定最佳的K值
plt.rcParams['font.sans-serif'] = ['SimHei']
inertia = []
for k in range(1, 20):
kmeans = KMeans(n_clusters=k, random_state=0,init="k-means++")
kmeans.fit(X1)
inertia.append(kmeans.inertia_)
# 绘制手肘法图表
plt.figure(figsize=(5, 3),dpi=144)
plt.plot(range(1,20), inertia, marker='o', linestyle='--')
plt.xlabel('K值')
plt.ylabel('距离平方和')
plt.title('手肘法图表')
plt.savefig('手肘法图.png',dpi=300)
# plt.grid(True)
# 设置横坐标刻度值为整数
plt.xticks(range(1, 20, 1))
plt.show()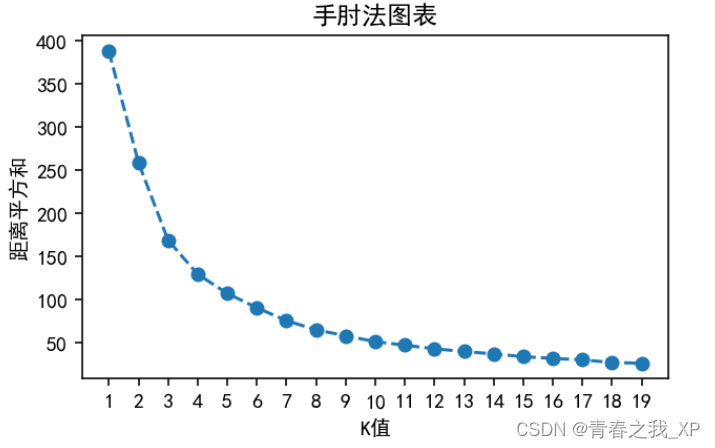
import numpy as np
# Find the K value with the smallest inertia change
#距离平方和得差,也就是每次K值距上一次K值所对应得距离平方和下降程度
inertia_diff = np.diff(inertia)
plt.figure(figsize=(5, 3),dpi=144)
inertia_diff_abs = np.abs(inertia_diff) # 取绝对值,使所有值变为非负
plt.plot(range(2, 20), inertia_diff_abs, marker='o', linestyle='--')
#inertia_diff_abs:取绝对值
plt.xlabel('K值')
plt.ylabel('距离平方和下降程度')
plt.title('目标函数(聚类内部元素的总平方距离下降程度)表')
# plt.savefig('手肘法图.png',dpi=300)
# plt.grid(True)
# 设置横坐标刻度值为整数
plt.xticks(range(2, 20, 1))
plt.show() 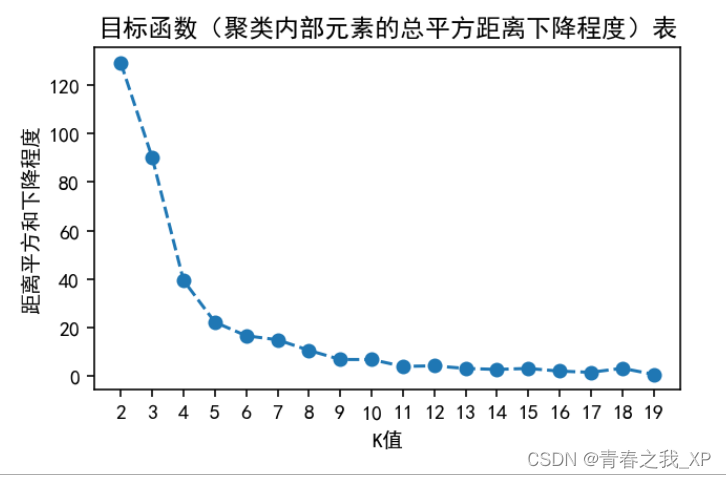
通过分析,K的最优取值为5。具体原理和分析过程,不在这里再具体阐述,感兴趣的小伙伴可以查看上一篇博客进行了解。链接如下:
[机器学习系列]深入解析K-Means聚类算法:理论、实践与优化-CSDN博客
(2)选择最优K值后,进行KMeans聚类
kmeans = KMeans(n_clusters=5, random_state=0)
kmeans.fit(X1)
print(kmeans.labels_)#获取训练数据所属的类别(3) 查看每个聚类后类别中的样本数
import pandas as pd
# 将 Y 转换为 Pandas Series
kmeans.labels_series = pd.Series(kmeans.labels_)
# 计算 Y 中每个类别的数量
class_counts = kmeans.labels_series.value_counts()
print(class_counts)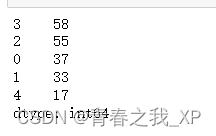
(4) 计算聚类后每个类别占多数类样本的比例
# 计算总数(所有类别的数量)
total_count = class_counts.sum()
# 计算每个类别占总数的比例
class_proportions = class_counts / total_count
print(class_proportions)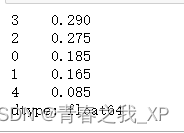
(5)计算聚类后每个类别中应该抽取的样本数
至于为什么*180,请参考(二)目的第一部分,其中有阐述。
class_proportions*180
那么按照四舍五入,标签为3的这一类从中随机无放回抽取52个样本,标签为2的这一类从中随机无放回抽取50个样本,标签为0的这一类从中随机无放回抽取33个样本,标签为1的这一类从中随机无放回抽取30个样本,标签为4的这一类从中随机无放回抽取15个样本.52+50+33+30+15=180.
(6)抽取数据
# 将 X 转换为 DataFrame
import pandas as pd
df = pd.DataFrame(X1, columns=['Feature1', 'Feature2'])
# 将簇标签添加到原始数据中
df["聚类标签结果"]=kmeans.labels_
df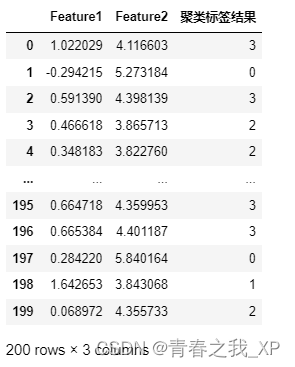
①随机无放回抽取33个标签为0的样本
cluster_zero_df = df[df["聚类标签结果"] == 0]
import pandas as pd
# 不放回地随机抽取33行数据
sampled_zero = cluster_zero_df.sample(n=33, replace=False)
# print(sampled_zero)
# 在这段代码中,sample函数用于从DataFrame中抽取样本。参数n=33指定了要抽取的样本数量,而replace=False确保了抽取是不放回的。②随机无放回抽取30个标签为1的样本
cluster_one_df = df[df["聚类标签结果"] == 1]
sampled_one = cluster_one_df.sample(n=30, replace=False)③随机无放回抽取50个标签为2的样本
cluster_two_df = df[df["聚类标签结果"] == 2]
sampled_two = cluster_two_df.sample(n=50, replace=False)④随机无放回抽取52个标签为3的样本
cluster_three_df = df[df["聚类标签结果"] == 3]
sampled_three = cluster_three_df.sample(n=52, replace=False)④随机无放回抽取15个标签为4的样本
cluster_four_df = df[df["聚类标签结果"] == 4]
sampled_four = cluster_four_df.sample(n=15, replace=False)⑤合并各类抽取后的数据
combined_df = pd.concat([sampled_zero, sampled_one, sampled_two, sampled_three,sampled_four], axis=0)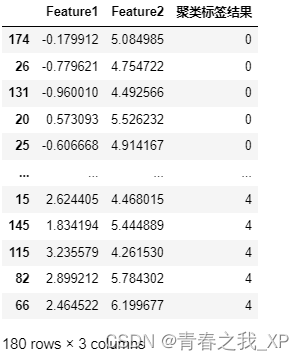
(四) 将180个多数类样本,和90个少数类样本进行整合。(目标就是多数类样本:少数类样本=2:1)
combined_df=combined_df.iloc[:, :2]
combined_df["标签"] = 0
df_0类样本=combined_df
df_1类样本= pd.DataFrame(X2, columns=['Feature1', 'Feature2'])
df_1类样本["标签"]=Y2+1 #这里Y2为什么加1呢,因为最开始我们生成数据集时,是分开分别生成了两对数据集X1 Y1 和 X2 Y2,实际上Y1和Y2的标签都是0,所以这里让Y2+1变成标签1
data= pd.concat([df_0类样本, df_1类样本], axis=0)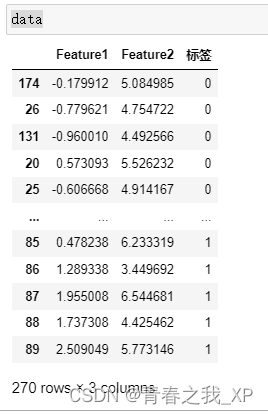

五、基于聚类的过抽样方法(K-Means过抽样)
K-Means过抽样的内容和Kmeans欠抽样几乎一致,
不过唯一的不同点就是:
K-means过抽样是以多数类样本为基础,对少数类样本进行聚类。
比如我们想要多数类样本N1_new:少数类样本N2_new=2:1
但是现在多数类样本N1=200,少数类样本N2=90,此时200:90不等2:1
如果以多数类样本N1=N1_New为基础不变,那么N2_new就得等于100,此时少数类样本N2有90个样本了,为了使数据信息充分被利用,那么少数类样本依然选择这90个数据,然后还缺100-90=10个少数类样本,此时就对90个少数类样本进行聚类,聚成K个簇
确定从每个簇中抽取的样本量ni:
ni=(N2_i/N2)*(N2_new-N2)
i=1,2,3,4,5,6......k(k个簇)
其中N2_i,代表第i个簇中的样本量,N2_i/N2代表第i个簇中的样本量占整个多类样本数量的比例
ni也就是确定的每个簇中抽取的样本量
N2_new是希望 抽样结束后,少数类样本的总个数
N2是原始数据中少数类样本的总个数
(N2_new-N2)是希望通过聚类过抽样抽取的少数样本总数。
六、python实现KMeans过抽样
(一)目的
我们想控制Y1类和Y2类的数量比例ratio是2:1,故若采取过抽样的话,以多数类样本数量200不动,少数类样本数量要从90变成100,那么就要将90个少数类样本进行聚类,然后按照比例从每簇中抽取数据,共从中随机无放回抽取出10个少数类样本。
(二)通过Kmeans对X2少数类样本进行聚类
(1)通过手肘法和目标函数确定KMeans的最优K值
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
# 使用手肘法确定最佳的K值
plt.rcParams['font.sans-serif'] = ['SimHei']
inertia = []
for k in range(1, 20):
kmeans = KMeans(n_clusters=k, random_state=0,init="k-means++")
kmeans.fit(X2)
inertia.append(kmeans.inertia_)
# 绘制手肘法图表
plt.figure(figsize=(5, 3),dpi=144)
plt.plot(range(1,20), inertia, marker='o', linestyle='--')
plt.xlabel('K值')
plt.ylabel('距离平方和')
plt.title('手肘法图表')
plt.savefig('手肘法图.png',dpi=300)
# plt.grid(True)
# 设置横坐标刻度值为整数
plt.xticks(range(1, 20, 1))
plt.show()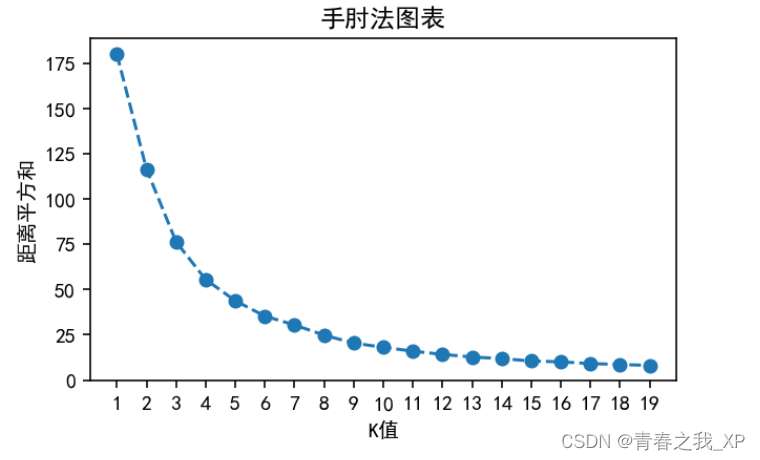
import numpy as np
# Find the K value with the smallest inertia change
#距离平方和得差,也就是每次K值距上一次K值所对应得距离平方和下降程度
inertia_diff = np.diff(inertia)
plt.figure(figsize=(5, 3),dpi=144)
inertia_diff_abs = np.abs(inertia_diff) # 取绝对值,使所有值变为非负
plt.plot(range(2, 20), inertia_diff_abs, marker='o', linestyle='--')
#inertia_diff_abs:取绝对值
plt.xlabel('K值')
plt.ylabel('距离平方和下降程度')
plt.title('目标函数(聚类内部元素的总平方距离下降程度)表')
# plt.savefig('手肘法图.png',dpi=300)
# plt.grid(True)
# 设置横坐标刻度值为整数
plt.xticks(range(2, 20, 1))
plt.show()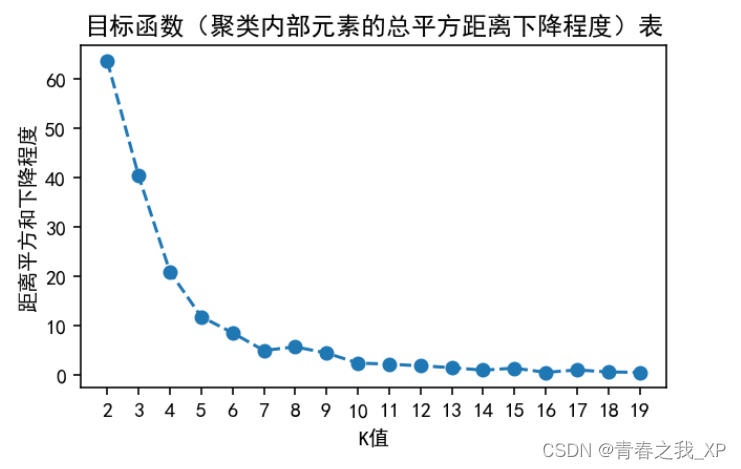
通过分析,K的最优取值为5。具体原理和分析过程,不在这里再具体阐述,感兴趣的小伙伴可以查看上一篇博客进行了解。链接如下:
[机器学习系列]深入解析K-Means聚类算法:理论、实践与优化-CSDN博客
(2)选择最优K值后,进行KMeans聚类
kmeans = KMeans(n_clusters=4, random_state=0)
kmeans.fit(X2)(3) 查看每个聚类后类别中的样本数
import pandas as pd
# 将 Y 转换为 Pandas Series
kmeans.labels_series = pd.Series(kmeans.labels_)
# 计算 Y 中每个类别的数量
class_counts = kmeans.labels_series.value_counts()
print(class_counts)
(4) 计算聚类后每个类别占少数类样本的比例
# 计算总数(所有类别的数量)
total_count = class_counts.sum()
# 计算每个类别占总数的比例
class_proportions = class_counts / total_count
print(class_proportions)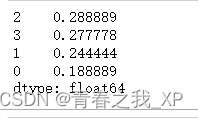
我们想使多数类样本:少数类样本=2:1,现在是过抽样,以多数类样本的数量200为基础不动,少数类样本应该是有100个,但是现在只有90个,所以需要对这90个样本进行聚类,聚成K个类,然后按照比例分别从这K个类中抽取样本,总共抽取的样本是10个,这样90+10=100少数类样本就一共有100个了,多数类样本:少数类样本就满足比例2:1了。
(5)计算聚类后每个类别中应该抽取的样本数
class_proportions*10
那么按照四舍五入,标签为2的这一类从中随机无放回抽取3个样本,标签为3的这一类从中随机无放回抽取3个样本,标签为1的这一类从中随机无放回抽取2个样本,标签为0的这一类从中随机无放回抽取2个样本.3+3+2+2=10.
(6)抽取数据
# 将 X 转换为 DataFrame
import pandas as pd
df = pd.DataFrame(X2, columns=['Feature1', 'Feature2'])
# 将簇标签添加到原始数据中
df["聚类标签结果"]=kmeans.labels_
df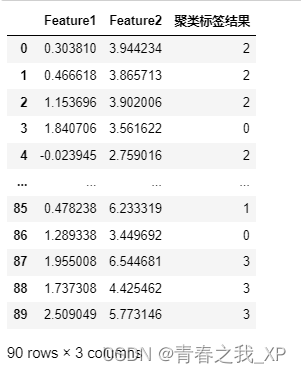
①随机无放回抽取2个标签为0的样本
cluster_zero_df = df[df["聚类标签结果"] == 0]
sampled_zero = cluster_zero_df.sample(n=2, replace=False)②随机无放回抽取2个标签为1的样本
cluster_one_df = df[df["聚类标签结果"] == 1]
sampled_one = cluster_one_df.sample(n=2, replace=False)③随机无放回抽取3个标签为2的样本
cluster_two_df = df[df["聚类标签结果"] == 2]
sampled_two = cluster_two_df.sample(n=3, replace=False)④随机无放回抽取3个标签为3的样本
cluster_three_df = df[df["聚类标签结果"] == 3]
sampled_three = cluster_three_df.sample(n=3, replace=False)⑤合并各类抽取后的数据
combined_df = pd.concat([sampled_zero, sampled_one, sampled_two, sampled_three], axis=0)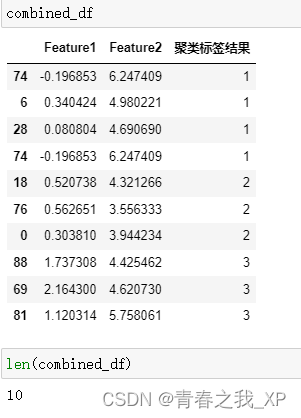
(三) 将200个多数类样本,和100个少数类样本进行整合。(目标就是多数类样本:少数类样本=2:1)
combined_df=combined_df.iloc[:, :2]
combined_df["标签"] = 1
df_1类抽样样本=combined_df
df_1类样本= pd.DataFrame(X2, columns=['Feature1', 'Feature2'])
df_0类样本= pd.DataFrame(X1, columns=['Feature1', 'Feature2'])
df_0类样本["标签"]=Y1
data= pd.concat([df_0类样本, df_1类样本,df_1类抽样样本], axis=0)